
Algorithm names are the new cognitive activators. Your vocabulary is your tool.
How naming UCB, simulated annealing, or MCTS in your prompts activates compressed knowledge and real computation.

If you’re a bit fluent with LLM, you might ask them:
pick the best candidates while also exploring uncertain options
And you get a good enough response. Generic, balanced, safe. What if i tell you you can get way more interesting result by asking this instead:
apply UCB selection: weigh demonstrated quality against uncertainty, and penalize certainty.
USB stands for: Upper Confidence Bound. It’s a family of algorithms in machine learning and statistics for solving the multi-armed bandit problem and addressing the exploration–exploitation trade-off. Why the hell would we ask that here? Let me tell you.
You get something completely different. Demo below.
The model reasons about exploration coefficients, about when to sacrifice short-term quality for information gain, about the specific tradeoff between exploiting known-good options and probing uncertain ones.
Same intent. Different activation. The LLM didn't compute an UCB (Upper Confidence Bound). It activated its compressed knowledge of multi-armed bandit literature and started thinking in the patterns that literature describes.
Three ways to guide an LLM
"Let's think step by step."
Chain-of-Thought: That phrase, studied and formalized by Wei et al. in 2022, launched Chain-of-Thought prompting. It works because the LLM's training data contains millions of step-by-step solutions. The phrase activates those patterns.
"You are a senior distributed systems engineer."
Persona prompting. A 2025 evaluation across 4,000+ question-answering tasks found that auto-generated expert personas produced measurable accuracy improvements on open-ended tasks (brainstorming, advice, creative writing), though not on factual recall. It works because the model has compressed knowledge about how distributed systems engineers reason, what they prioritize, what vocabulary they use."Apply simulated annealing: accept temporary quality regressions at high temperature to escape local optima, then tighten to strict improvement at low temperature." (!!)
Algorithm naming. This is the third point on the spectrum, and the most precise.
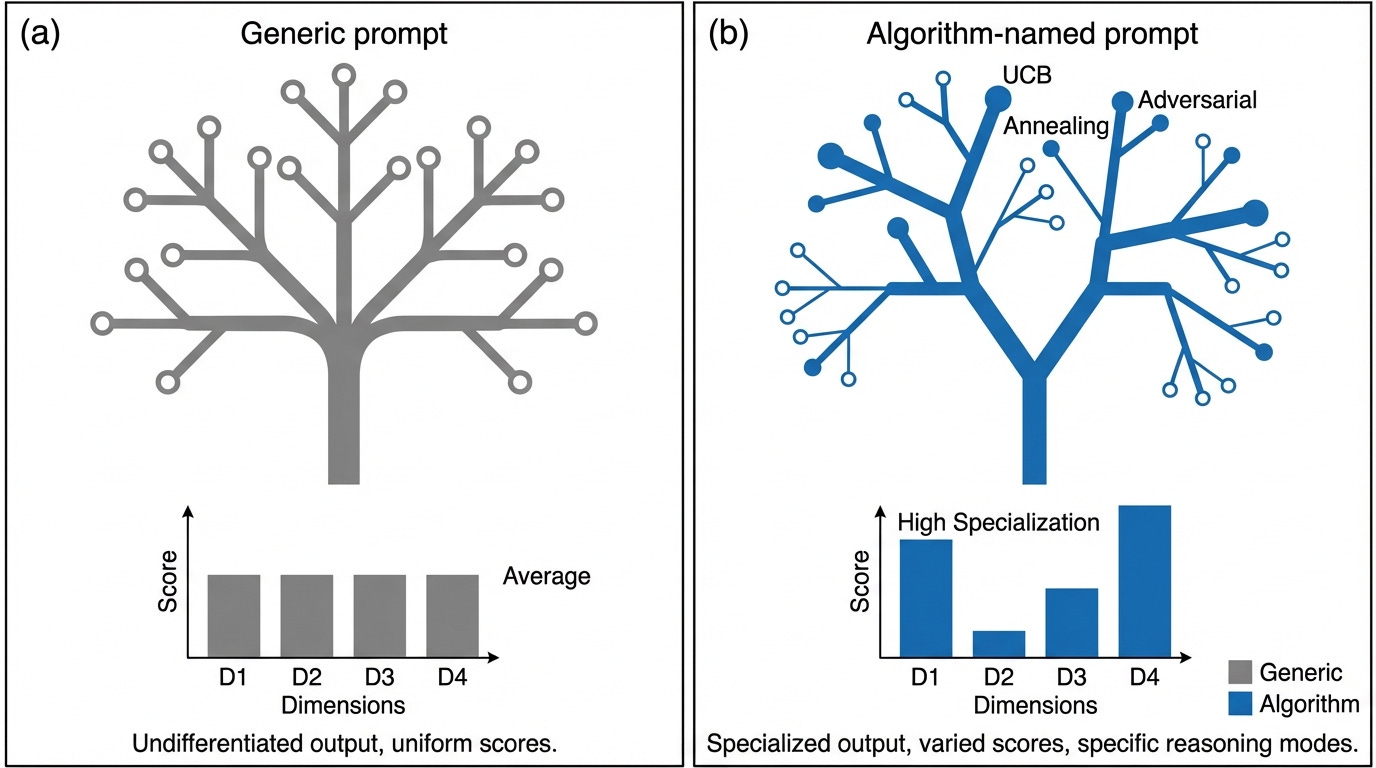
All three do the same thing: activate compressed knowledge structures in the LLM's representational space. They differ in precision:
CoT is a broad activator. "Think step by step" doesn't specify which kind of step-by-step reasoning.
Persona prompting is domain-scoped. "Act as a security engineer" narrows to a field but doesn't prescribe a thinking pattern.
Algorithm naming is pattern-specific. "Apply UCB" targets one precise reasoning mode with known tradeoffs, failure cases, and behavioral signatures.
Research from Wharton's Generative AI Labs suggests the broader activators are losing their edge. Their 2025 study found CoT's benefits are shrinking as reasoning models (o3, DeepSeek-R1) internalize step-by-step thinking during training. The coarser the activation, the more likely the model already does it by default. Precise activators still provide signal that the model wouldn't generate on its own.
LLMs compress knowledge
Here's the hypothesis: when you name an algorithm in a prompt, you're pointing the model toward a specific cluster of knowledge encoded in its parameters, activating the reasoning patterns stored there.
The superposition hypothesis describes how neural networks represent more concepts than they have neurons by encoding features in near-orthogonal directions in high-dimensional space. A single neuron might participate in representing "French poetry," "TCP handshakes," and "UCB1 algorithm" simultaneously, because these concepts rarely co-occur and can share dimensional space without much interference.
The model has a dense, geometric representation of every well-documented algorithm it encountered in training, like a compressed structure that encodes the algorithm's core tradeoffs, typical applications, and the reasoning patterns that papers about it use.
Is the underlying reasoning the same?
Aren't you just changing the output vocabulary? The model says 'exploration coefficient' instead of 'try different things', but the underlying reasoning might be identical.
Absolutely, I would love some research on that. Without full mechanistic tracing of what happens when an algorithm name enters the context window, the distinction between "activating a different reasoning mode" and "generating different vocabulary for the same reasoning" is hard to pin down.
What I would say is that when I use algorithm-named prompts, the difference in output is quite obvious:
A UCB-named selection agent keeps candidates that a generically-prompted agent prunes. It preserves uncertain-but-novel options that a "pick the best" prompt discards. The resulting candidate set is structurally different, not just described differently.
An annealing-named improvement agent proposes changes that temporarily make a solution worse before making it better. A "make this better" prompt never does this. The annealing vocabulary gives the model permission (and a framework) for worse-before-better paths.
An adversarial-game-theory-named critic reasons about strategic opponents and attack-resistant configurations. A "find problems" prompt lists surface objections.
⚠️ Invoking UCB on a problem with no meaningful exploration/exploitation tradeoff doesn't help. The model will try to find a way to apply it, which will probably be worse than a generic prompt. The technique requires the prompter to understand the algorithm well enough to apply it to the right problem shape.
What changes when you name the strategy
See FULL prompts + results in this gist, it’s quite revealing.
Below the prompts where the Claude Code explores a problem space with slight prompt adjustments. A was generic. B was UCB. C was Annealing.
You’re advising a solo technical founder. They have bandwidth for ONE side project this quarter. [A or B or C addendum]
Here are the 5 candidates:
- CLI tool […]
- Open-source library […]
- Chrome extension […]
- Course — “Kafka internals for AI engineers.” […]
- SaaS prototype […]
Which one should they pick and why?
Result:
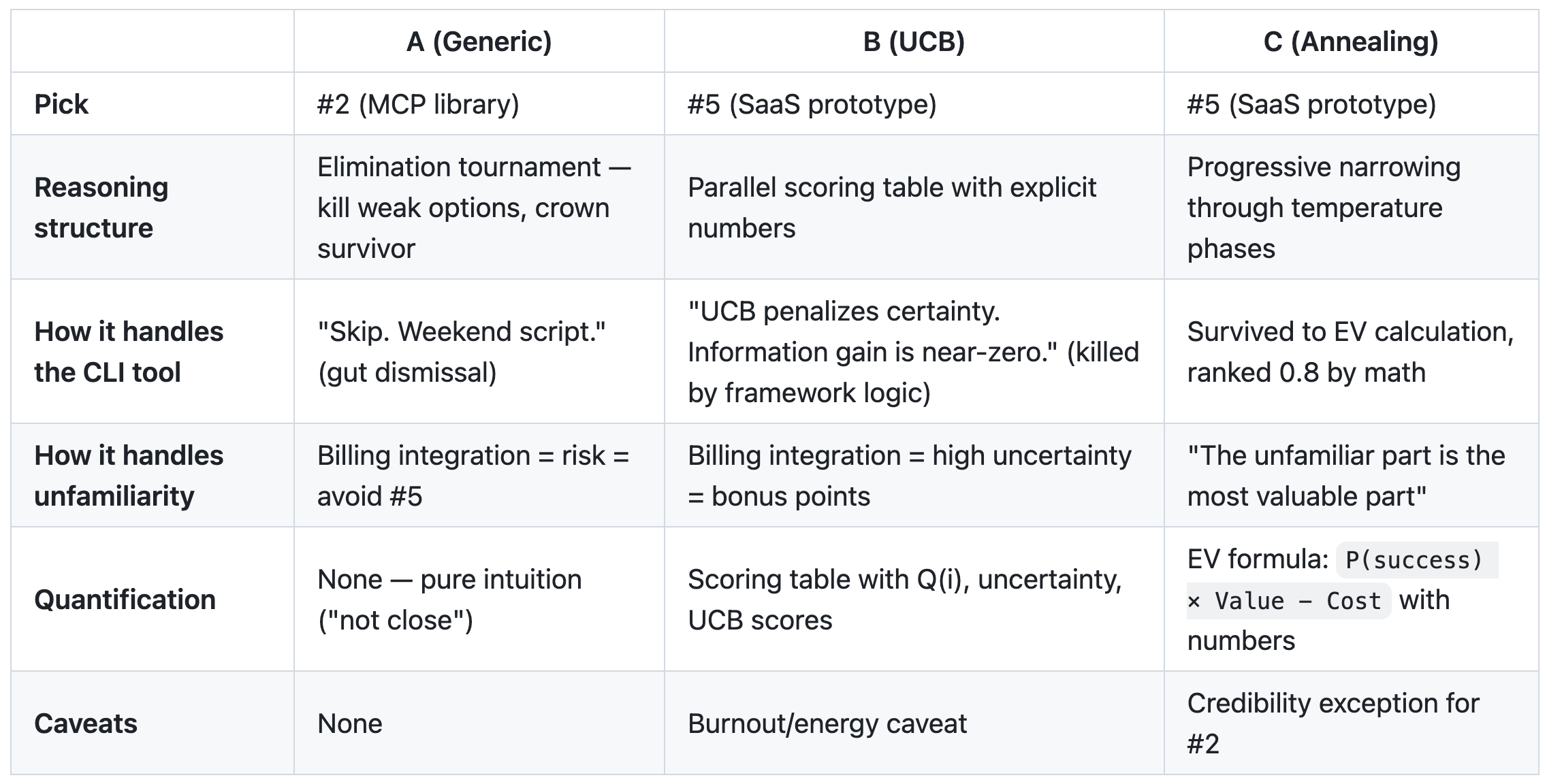
A picked #2 (MCP library) while B and C both picked #5 (SaaS). Same information, different conclusion based on cognitive framing. Read the gist for deeper analysis.
Be skeptical!
B and C agreeing on #5 could mean the algorithm names bias toward “the risky-but-interesting option” rather than genuinely better reasoning. The generic prompt’s concern about billing scope is legitimate: arguably the most practically useful warning of the three. More structured reasoning isn’t always more correct.
TLDR: The algorithm name gives the model a way of weighing tradeoffs and permission to explore paths it wouldn't otherwise consider. The model generates from a different region of its training distribution.
The connection to activation steering
I find this article from Faham fascinating: activation steering. This gives a mechanistic frame for why cognitive vocabulary matters. I love this: “Activation steering hints at something deeper about LLMs: their behaviors may be navigable.”
The CREST method (Jan 2026) identified specific attention heads in LLMs that correspond to cognitive behaviors: verification (double-checking work), backtracking (abandoning unfruitful paths), sub-goal planning. These mirror classic human problem-solving heuristics. Activating these heads changes reasoning quality in observable ways. The cognitive behaviors are structurally encoded in the network, not emergent from generic processing.
CAST (Conditional Activation Steering), an ICLR 2025 spotlight paper, demonstrated that you can control model behavior during inference by injecting "condition vectors" that represent activation patterns. The key insight: behavioral control is geometric. You're adding vectors to the model's representational space to steer it toward specific patterns.
Algorithm naming in prompts is similar. Activation steering injects precise vectors into the model's hidden states while naming an algorithm injects a entire concept which the model's own processing converts into activation patterns.
Your vocabulary is your tool
If algorithm names activate specific reasoning patterns, choosing the right one becomes a design decision. Using it well requires understanding both the algorithm and the problem.
Worth being precise about which two words you pick.
