
Fixing the Agent Data Layer: Six Patterns
Tool design, schema discovery, search APIs, and the data layer agents need.

Agents don't have a model problem, they have a data problem. Prompt engineering is not enough to help here.
Shipping AI agents is shipping data pipelines. Let’s see how.
Before fixing: Measure
Tuning prompts on an agent is debugging in the dark. Before changing anything, get these numbers per agent:
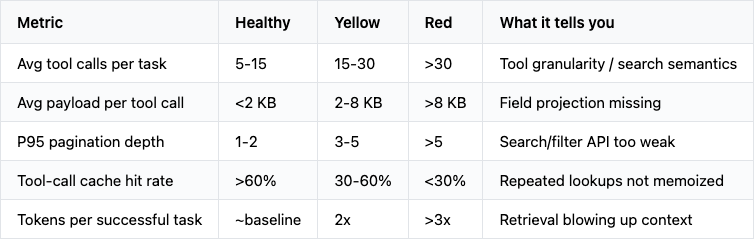
Send these traces into whatever collector you’re already using. LangSmith and Phoenix capture payload sizes and tool call hierarchies natively, which is what you need here. A simple Postgres table works too: [task_id, tool_name, payload_bytes, latency_ms, cache_hit, ts]. The spans must carry payload size. This will become important to understand the “shape” of the work done by the agents. Customer support agents look different from coding agents look different from analytics agents.
The shape of the distribution matters more than the absolute numbers.
Pattern 1: How to make a Search API for LLMs
We love search. Agents love it. We always design it like: "match the query (“LIKE ‘%xxx%’”), return up to N results." For agents this is really BAD.
Why? The agent doesn't know which fields to filter on, what valid values look like, or how to narrow the result set. So it paginates, it’s slow and you lose precious token context space; or it gives up and asks the user to clarify.
The fix is to make the search API talk back when overwhelmed. For instance, this is bad, as it dumps results and agents has no path forward:
GET /search/tickets?q=urgent
{
"results": [ /* 4,231 tickets */ ],
"next_cursor": "eyJvZmZzZXQiOjUwfQ=="
}This is better:
GET /search/tickets?q=urgent
{
"result_count": 4231,
"returned_count": 0,
"guidance": "Too many matches. Filter by one of: status (open|pending|closed), priority (p0|p1|p2|p3), assigned_to (user_id), or opened_after (ISO date). Common narrowing combos: {status='open', priority IN ('p0','p1')} typically returns <50.",
"available_filters": {
"status": { "values": ["open","pending","closed"], "cardinality": 3 },
"priority": { "values": ["p0","p1","p2","p3"], "cardinality": 4 },
"assigned_to": { "type": "user_id", "cardinality": 142 },
"opened_after": { "type": "iso_datetime" }
},
"sample_records": [ /* 3 representative tickets, minimal fields */ ],
"suggested_refinement": "GET /search/tickets?q=urgent&status=open&priority=p0"
}An LLM can read and adapt. So it will read the guidance and available_filters and reissues a tighter query. You trade big responses for tiny ones. Net token cost drops by an order of magnitude, the agent is faster, and you have a better audit log to understand usage of your API.
You can pair this into a CLAUDE.md or a SKILL.md:
When a search tool returns guidance, treat it as instruction. Do not
paginate broad searches; refine using the available_filters instead.
If result_count > 50, you must narrow before fetching records.Make the API teach the model how to use it. This is similar for MCP tools.
Pattern 2: MCP & Field projection
We’re using Zendeck to run customer support. A typical Zendesk ticket, full payload, is several kilobytes of JSON. Same with any enterprise SaaS. Most tool calls in an agent session need 5-10% of those fields. Returning the rest is paying tokens to read nothing. Do you know https://github.com/rtk-ai/rtk? It’s a CLI that reduces LLM token consumption by 60-90% on common dev commands (git, ls, etc.). Do the same with data, trim it down for the LLM.
The MCP tool definition should default to a minimal projection and let the agent opt into more. This is bad as this will return full records every time, polluting context and derailing attention:
{
"name": "get_ticket",
"description": "Get a ticket by id.",
"inputSchema": {
"type": "object",
"properties": { "id": { "type": "string" } },
"required": ["id"]
}
}This is better:
{
"name": "get_ticket",
"description": "Get a ticket by id. Returns minimal fields by default (id, status, subject, priority, assignee_id, last_update_at). Pass include_fields for extras. Avoid include_fields=['*'] unless you've narrowed to a single record.",
"inputSchema": {
"type": "object",
"properties": {
"id": { "type": "string" },
"include_fields": {
"type": "array",
"items": {
"enum": [
"body",
"comments",
"attachments",
"history",
"internal_notes",
"custom_fields"
]
},
"description": "Optional extra fields. Each field's approximate size is noted in the enum doc."
}
},
"required": ["id"]
}
}Tell the model what are the defaults
Give per-field hints and you can also provide the average size of them, so the model can protect its context window and be cautious.
Same pattern for any list MCP endpoints. The default should be thin: id, status, one display label for interpretation. Anything richer is a get_* call after the agent needs more on specific records. Again, that will also help you understanding which one are being actively queried and used. LLMs strive with metadata.
Pattern 3: Task-shaped tools, not CRUD wrappers
This is is probably the most important, and everyone is doing the same mistake. MCP is not just another wrapper of your REST endpoints.
The natural temptation when wrapping an existing API is to do CRUD: update_ticket(id, fields). Done. The agent now has the same surface area a developer using the API has. This is generic, the LLM will be happy, right?
No. The agent doesn't know your business rules about which field combinations are valid. Update with status=closed but no resolution_note? The endpoint will fail. Hopefully you have a good error messages, for the LLM to understand what happened and retry, right?
Give the model choice. Better to have five well-named tools aka intents than one tool with many params doing a bit of everything. Github MCP is quite good at this: get_latest_release, add_comment_to_pending_review, add_issue_comment. Just reading the tool names, their intent is super clear. The following is bad, one CRUD tool, all the danger surface:
@tool
def update_ticket(id: str, fields: dict) -> Ticket:
"""Update fields on a ticket."""
...This is better, multiple task tools, business rules baked in:
@tool
def mark_ticket_resolved(
id: str,
resolution_note: str, # required, business rule
resolution_category: Literal["fixed","duplicate","wont_fix","user_error"],
) -> Ticket:
"""Close a ticket as resolved. Requires a resolution note and category.
Use this for tickets where the customer's issue is solved.
Do NOT use for tickets escalated to engineering (use escalate_ticket)
or reassigned to another agent (use reassign_ticket)."""
...
@tool
def escalate_ticket(
id: str,
target_team: Literal["eng","billing","trust_safety"],
reason: str,
severity: Literal["p0","p1","p2"],
) -> Ticket:
"""Hand a ticket off to a specialist team. Use when the issue is
outside support's authority. Sets priority and notifies the on-call."""
...
@tool
def reassign_ticket(
id: str,
new_assignee_id: str,
handoff_note: str,
) -> Ticket:
"""Reassign to another support agent. Use for shift handoffs or
expertise routing. Does NOT change ticket status."""
...
@tool
def add_internal_comment(id: str, comment: str) -> None:
"""Add an internal-only note. Not visible to the customer."""
...
@tool
def request_customer_info(id: str, message: str, fields_needed: list[str]) -> None:
"""Email the customer asking for specific information. Sets status=pending."""
...Each tool name describes a specific intent. The model reads five descriptions and picks the closest match.
Useful side effect:
When something goes wrong in a task trace, you see mark_ticket_resolved not a generic update_ticket. Audit logs become useful and fast to interpret.
Permissions become per-intent: support agents can resolve, only leads can escalate. No complicated permissions mechanisms in a large “update” method.
Pattern 4: Schema introspection as a MCP tool
If your agent only sees raw record data (JSON), it has to learn what each field means. Sometimes, it may not be obvious and the LLM might misinterpret or ignore a valuable piece of information. Do you know GraphQL introspection? Make the schema itself queryable through a MCP tool:
@tool
def list_schemas() -> dict[str, str]:
"""List the data domains available to query.
Returns a map of schema_name -> one-line description. Call this first
when working with unfamiliar data."""
return {
"tickets": "Customer support tickets. ~1k new/day. Volatile.",
"accounts": "Customer accounts. ~50k total. Slow-changing.",
"users": "Internal users (support staff). ~150 total.",
"kb": "Knowledge base articles. ~800 total. Slow-changing."
}
@tool
def describe_schema(name: str) -> SchemaDescription:
"""Get fields, types, valid values, and common filters for a schema.
Always call this before constructing a complex query against an
unfamiliar schema."""
return SchemaDescription(
fields={
"status": FieldInfo(type="enum", values=["open","pending","closed"], indexed=True, useful_filter=True),
"priority": FieldInfo(type="enum", values=["p0","p1","p2","p3"], indexed=True, useful_filter=True),
"subject": FieldInfo(type="text", indexed_fulltext=True),
"body": FieldInfo(type="text", size_kb=1.2, lazy=True),
"assignee_id": FieldInfo(type="user_id", indexed=True, useful_filter=True),
# ... more fields
},
common_queries=[
"open tickets by priority",
"tickets opened in the last 24h",
"tickets assigned to a user",
],
anti_patterns=[
"fulltext search on body without status/priority filter (slow, 2-4s)",
"fetching include_fields=['*'] in list responses (token bomb)",
]
)You can help the LLM by adding this to the prompt:
Before querying an unfamiliar data domain:
1. Call list_schemas to see what's available.
2. Call describe_schema to learn fields and useful filters.
3. Construct narrow queries using indexed/useful_filter fields first.
4. Only request lazy fields if the task needs them.This costs ~500 tokens of upfront discovery on a cold task. It saves more than that on the first poorly-shaped query you avoid.
To go cheaper, inject the schema descriptions into the context directly. It depends on how many schemas you have.
Pattern 5: MCP Auth in a Gateway, not in the agent config
A multi-source agent that holds its own credentials is a key-management nightmaretoken rotation, OAuth refresh, per-environment secrets, token sharing, audit. A better pattern is:
one agent-side token bearer
an MCP gateway that holds OAuth on behalf of the user. Per-source credentials living in the gateway.
[Agent]
| Authorization: Bearer <agent-session-token>
v
[MCP Gateway]
| Looks up: session -> user -> per-source OAuth tokens
| Refreshes tokens as needed
| Logs every tool call with user attribution
v
[Source A] [Source B] [Source C] ...What you get:
The agent holds one short-lived token only.
Token refresh, expiry, and revocation happen in one place.
Audit logs in one place
Per-tool authorization (this user can read tickets but not resolve them) lives at the gateway, not scattered across N source integrations.
What it costs? Infrastructure.
The gateway is a real piece of infrastructure (availability and security implications). In short, it’s a secrets manager that must be ultra-safe.
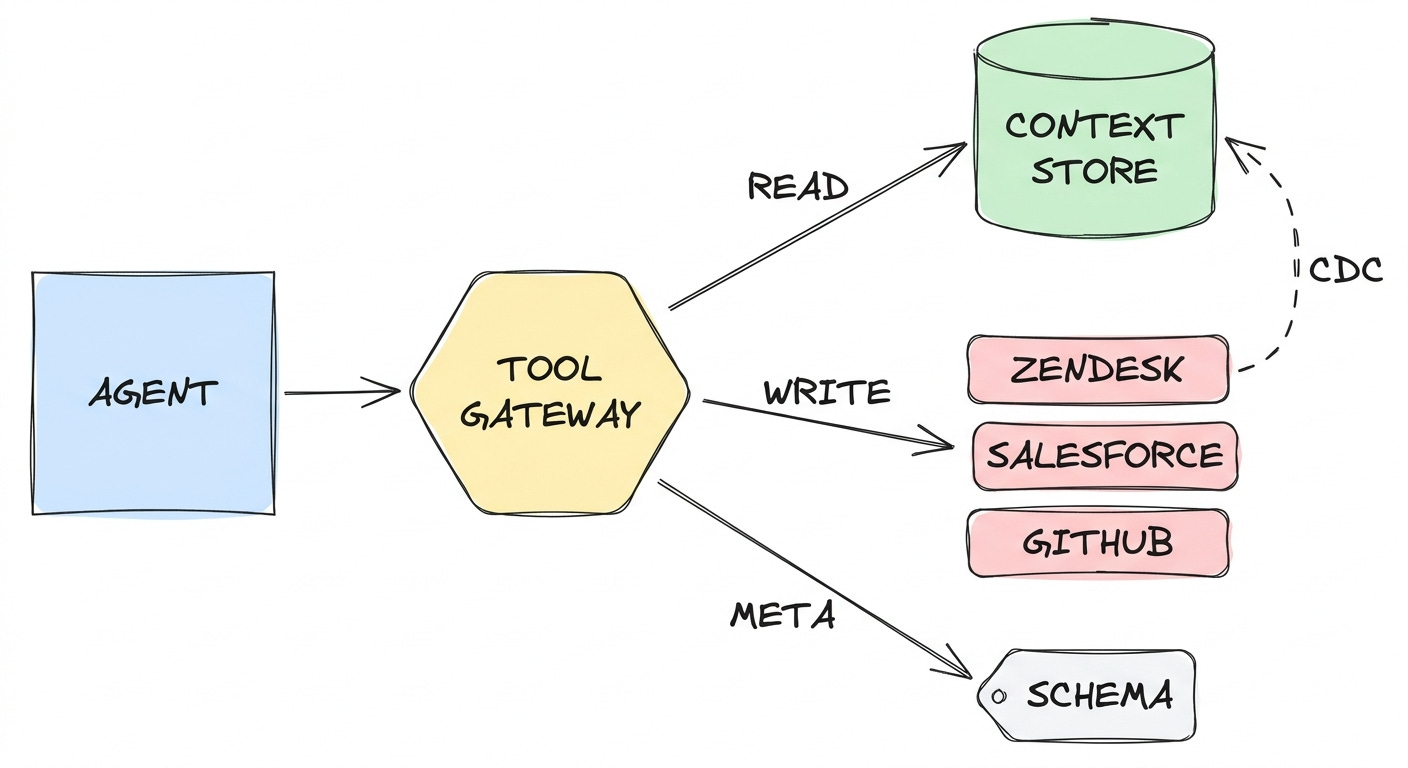
Pattern 6: Context Stores: Replication VS Proxy
A context store is a local indexed mirror of source data, kept in sync by some process and queried by the agent instead of the source system.
Think of it as a small purpose-built data warehouse tuned for an LLM consumer (specific fields, metadata, useful search APIs). The agent talks to this “mirror”; the mirror talks to the source. When is this useful?
Having a local context store may be useful if:
You need powerful querying mechanisms like vector based search or summaries
Source API is bad: poor filtering, fat payloads, no fulltext, rate limits
You need cross-source joins and aggregations
You want historical data and the source is not keeping it
Data fairly static / not frequently updated
Proxy directly to the source when ANY of these hold:
You need real-time / write-through
The source already has a strong query language (SQL or deep REST surface)
Data is sensitive
You can also go hybrid:
replicate the read path (remote to local): Postgres + pgvector; refreshed via change-data-capture (Debezium), ETLs (Fivetran), your own poller, whatever fits the source’s webhook/event capabilities.
proxy the write path (see Pattern 5)
READ (cached, fast, summarized)
Agent ---> Context Store (Postgres + pgvector)
^
| CDC / webhooks
|
Agent ---> Source API (direct, real-time)
WRITE (canonical)TLDR
Tuning the prompts is the tip of the iceberg. It’s fun but one needs to fix the real challenge with agentic workflow: bringing the Data to the agents.
Most fixes look like data engineering because they are:
caching
indexing
filtering, projecting
querying
cost, latency
The data layer is the agentic bottleneck.