
Linearizability vs serializability vs strict serializability: building the right intuition
Two properties, two communities, one persistent confusion

In late 2024, Jepsen tested Bufstream, a Kafka-compatible streaming system, and found it losing acknowledged writes in healthy clusters. No network partitions, no node crashes. Just writes vanishing. Around the same time, they traced lost updates in etcd to the jetcd client library silently retrying failed transactions, causing committed transactions to appear as failures. The server was correct. The client broke the guarantee.
This is what happens when consistency models are misunderstood. Not by users. By the systems themselves.
Linearizability and serializability are the two most confused terms in distributed systems. They sound similar. They both involve "ordering operations". They come from completely different worlds:
linearizability from the shared-memory / formal verification community,
serializability from the database community.
Different questions, different granularities, different trade-offs.
The baseline: single thread, no concurrency
One thread. One object. Operations happen one after another.
Both linearizability and serializability try to recover something close to this clarity for the messy world where multiple threads or processes operate concurrently. They just recover different aspects of it.
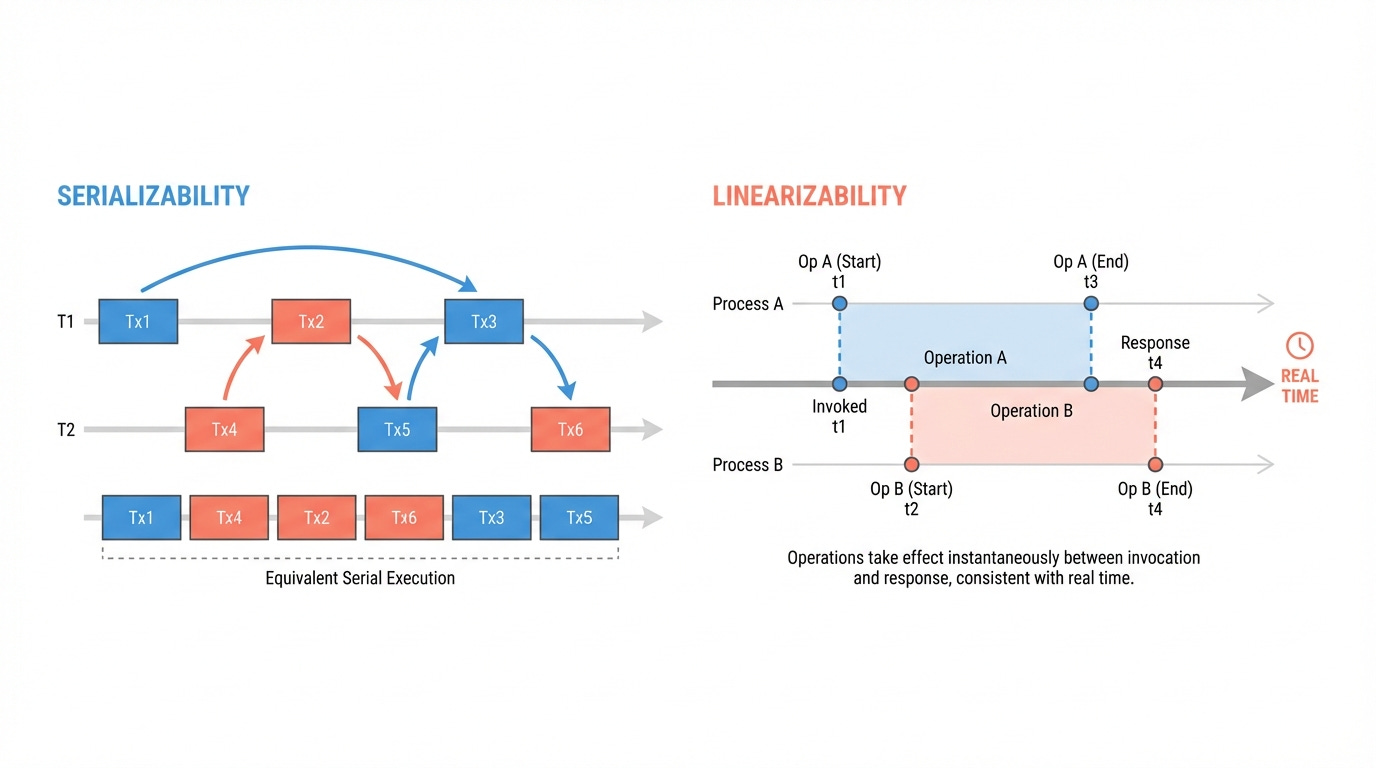
Serializability: "some serial order exists"
Serializability comes from databases. It deals with transactions, groups of operations that span multiple objects.
A system is serializable if the outcome of executing transactions concurrently is equivalent to executing them in some serial order. Not necessarily the real-time order. Any valid serial order will do.
Example: Consider an e-commerce system. Two transactions run concurrently:
T1: Customer places an order. Decrement inventory for item X, create an order record, charge the payment.
T2: Admin generates a report. Read inventory for item X, read total orders, read revenue.
In real time, T1 commits at 10:00:00. T2 starts at 10:00:01.
A serializable system is allowed to order these as T2 -> T1. The report sees the old inventory, the old order count, the old revenue. T1's order hasn't "happened" yet from T2's perspective, even though T1 committed first in wall-clock time.
This feels wrong. The admin pulled the report after the order completed. But serializability says this is fine, because there exists a serial order (T2 then T1) that produces a consistent result. The report's numbers all agree with each other. No partial state leaked. Consistency is the key here. The chosen order has nothing to do with when things actually happened.
What most databases actually give us something weaker by default.
PostgreSQL defaults to read committed.
Oracle defaults to read committed.
MySQL defaults to repeatable read.
Serializable isolation is opt-in, as it costs throughput.
Linearizability: "each operation snaps into place"
Linearizability comes from the shared-memory and formal verification community (Herlihy & Wing, 1990). It deals with individual operations on single objects, a register, a counter, a queue…
Each operation appears to take effect atomically at a single point between its invocation and its response. And if operation A completes before operation B starts, A must appear before B. Real-time order must be preserved.
Example: Let's take a FIFO queue. Two processes, P and Q, enqueue items concurrently:
P: |--- Enq(x) ---|
Q: |--- Enq(y) ---|
P: Deq() -> ??? x or y ?P's enqueue and Q's enqueue overlap. Their linearization points (the instant each "takes effect") can be placed in either order within their intervals. Both Enq(x)-then-Enq(y) and Enq(y)-then-Enq(x) are valid linearizations.
If we pick Enq(y) first: the queue is [y, x]. Deq returns y. Valid.
If we pick Enq(x) first: the queue is [x, y]. Deq returns x. Valid.
If we remove the overlap:
P: |--- Enq(x) ---|
Q: |--- Enq(y) ---|
P: Deq() -> y ? <- NO, NOT linearizable!Enq(x) finishes before Enq(y) starts. Real-time order forces Enq(x) before Enq(y). The queue must be [x, y]. Deq must return x. Returning y violates linearizability.
A last one:
P: |--- Enq(x) ---|
Q: |--- Enq(y) ---|
P: Deq() -> x
Q: Deq() -> x <- NOT linearizableThis has nothing to do with ordering. x was enqueued once and can only be dequeued once. The sequential specification of a FIFO queue prohibits this, and linearizability requires that every concurrent history correspond to a valid sequential history. No valid sequential history dequeues the same item twice.
Three rules:
No overlap between two operations -> real-time order is forced
Overlap -> either order is a valid linearization
The sequential spec decides -> once the order is fixed, the result must match what the data structure would produce sequentially
The three axes
Three properties separate these models, each pointing in opposite directions:

Composability is the sleeper property
Two linearizable objects composed together? The system is linearizable. This is Herlihy and Wing's Theorem 1. You build each concurrent object in isolation, prove it linearizable, deploy them all together, and the whole system is linearizable. No global coordination needed.
Serializability doesn't have this property. Two subsystems, each individually serializable, may not be serializable as a whole. ⚠️ The reason: serializability requires a global serial order across all objects. Without a shared concurrency control mechanism, independent subsystems can produce executions where no single global serial order is consistent. This is why serializable databases need a unified concurrency control protocol, and why you can't trivially federate two serializable databases into one serializable system.
Strict serializability: the ultimate combination
Sometimes you need both. You want multi-object transactions (serializability) that also respect real-time ordering (linearizability). This combination is called strict serializability, or what Google calls external consistency.
Google Spanner achieves external consistency across globally distributed data centers. The mechanism: TrueTime, a clock service backed by GPS receivers and atomic clocks, with a bounded clock uncertainty between nodes (typically single-digit milliseconds). When a transaction commits, Spanner's commit-wait protocol pauses until it's certain the commit timestamp is in the past for all observers. This converts wall-clock uncertainty into a brief wait, typically invisible thanks to the tight bounds.
CockroachDB pursues similar goals without atomic clocks, using a hybrid logical clock scheme with a larger uncertainty window and different trade-offs around clock skew.
When people say they want a "strongly consistent" database, they usually mean strict serializability. Not plain serializability (which can reorder across real time), and not plain linearizability (which doesn't handle multi-object transactions).
Where this plays out in practice
Distributed coordination services
etcd provides linearizable reads and writes on individual keys via Raft consensus.
ZooKeeper provides linearizable writes via ZAB, but reads are sequentially consistent by default: a `sync()` call is required before a read for linearizable semantics.
This is single-object consistency, each key is a separate linearizable register. It’s why these systems are used for leader election and distributed locking: you need the guarantee that a read reflects the most recent write, in real time.
In 2024, Jepsen traced lost updates in etcd to a bug in the jetcd client library (version 0.8.2). The client retried failed transactions, causing transactions to be submitted twice, and committed transactions to appear as failures. The consistency model was correct at the server level. The client library broke it.
CAS and memory-level linearizability
Java's AtomicInteger.compareAndSet(), Go's sync/atomic, Rust's std::sync::atomic expose compare-and-swap operations. With appropriate memory ordering, each CAS is a linearizable operation on a single memory location.
Every lock-free data structure you've used (concurrent queues, skip lists, lock-free hash maps) is built on linearizable CAS operations composed together. Because linearizability is a local property, each object can be verified independently, and composing them preserves linearizability with no additional coordination.
When to use which
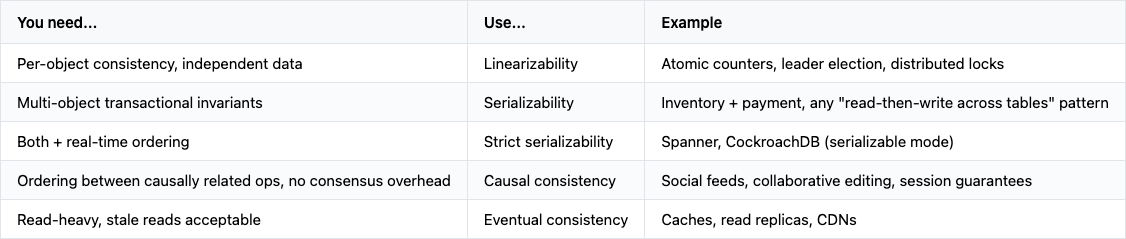
The mistake people make: using serializability terminology when they mean linearizability.
Kleppmann's Designing Data-Intensive Applications (Chapter 9) covers this material thoroughly, and the original Herlihy & Wing paper remains the definitive source for linearizability.