
Loop Engineering: When Generation Gets Cheap, Judgment Gets Expensive
Agentic loops make code, plans, and PRs abundant. The scarce part is knowing what is right.

I’m CTO, I prompt a lot. Always a few lines: context, a couple of directions, the goal, the constraints, the data/tools to use. I let Claude/Codex handle the what and the how.
I build many POCs, Github projects, and business projects at conduktor.io, engineering, marketing, SEO, support tickets, operations, so I’m spawning agents constantly in parallel, not just on code. I’m good at context switching.
One trick I use: I often add “I’m going to sleep”, hit enter, and run away. This way, Claude does not need me and does not interrupt itself.. One day, writing some marketing content, a dynamic workflow (the new Claude thing) drained my entire Max quota in a few minutes. It had spawned hundreds of agents:
some went gathering knowledge
some pulled code and state
a whole batch wrote actual programs whose only job was to verify each facet I'd asked about, so the thing could tell me, with proof, whether the code and the claims were 100% correct.
Read again: A few lines in… hundreds of agents out: millions and millions of tokens consumed and hours of work. This is where AI is going: cheap generation, expensive judgment.
I don't prompt anymore
I don’t write step-by-step prompts anymore. I write the root prompt: context, goal, constraints, and how success will be judged. We’ve all been growing with AI:
1/ Prompt engineering: being smart at prompting, that was even a job!
2/ Context engineering: what to retrieve/remove in the context window
3/ Harness engineering: how to build a run (which tools, which actions, what counts as "done").
4/ Loop engineering (2026!): making it run itself, over and over.
Each stage is expanding on the previous one. The new stage in 2026 (it seems to be called “loop engineering”) is a bit different. Before, it was still human-centric, with the human steering the agent. The loop is about agents steering agents. We’re no longer inside the loop doing the work. We’re outside it, building the thing that does the work: prompting Claude/Codex to prompt itself recursively.
That workflow that ate my quota? Not my fault? Kind of. I didn’t write the sub-prompts, yet I did define the root conditions that allowed the loop to run that far. I didn't decide all the steps and their depth, or that the verification agent should write a program, test it in Docker etc.
The model did all of that from my five lines. It broke my goal into steps, determined techniques per step, added some checks between them, then ran a top-down pass to fold the results per step and iterate.
I literally wrote such an orchestrator a year ago, I was really proud of it, it was amazing to handle the wiring, cross-agent communication, prompt generation, etc. It’s totally useless now.
The sub-prompts, the glue, the "ok now take this output and feed it there." That part is gone. What's left is the root of it: the context, the goal, what I actually care about, the constraints (time, budget, thoroughness, exactness). You have to know all of this to maximize your efficiency with AI, not just tell it “what” to do (the task itself), otherwise it means you lack the intel, the context, the “why”, therefore, AI/someone who knows this can just replace you and do the task better as they will have a better judgment.
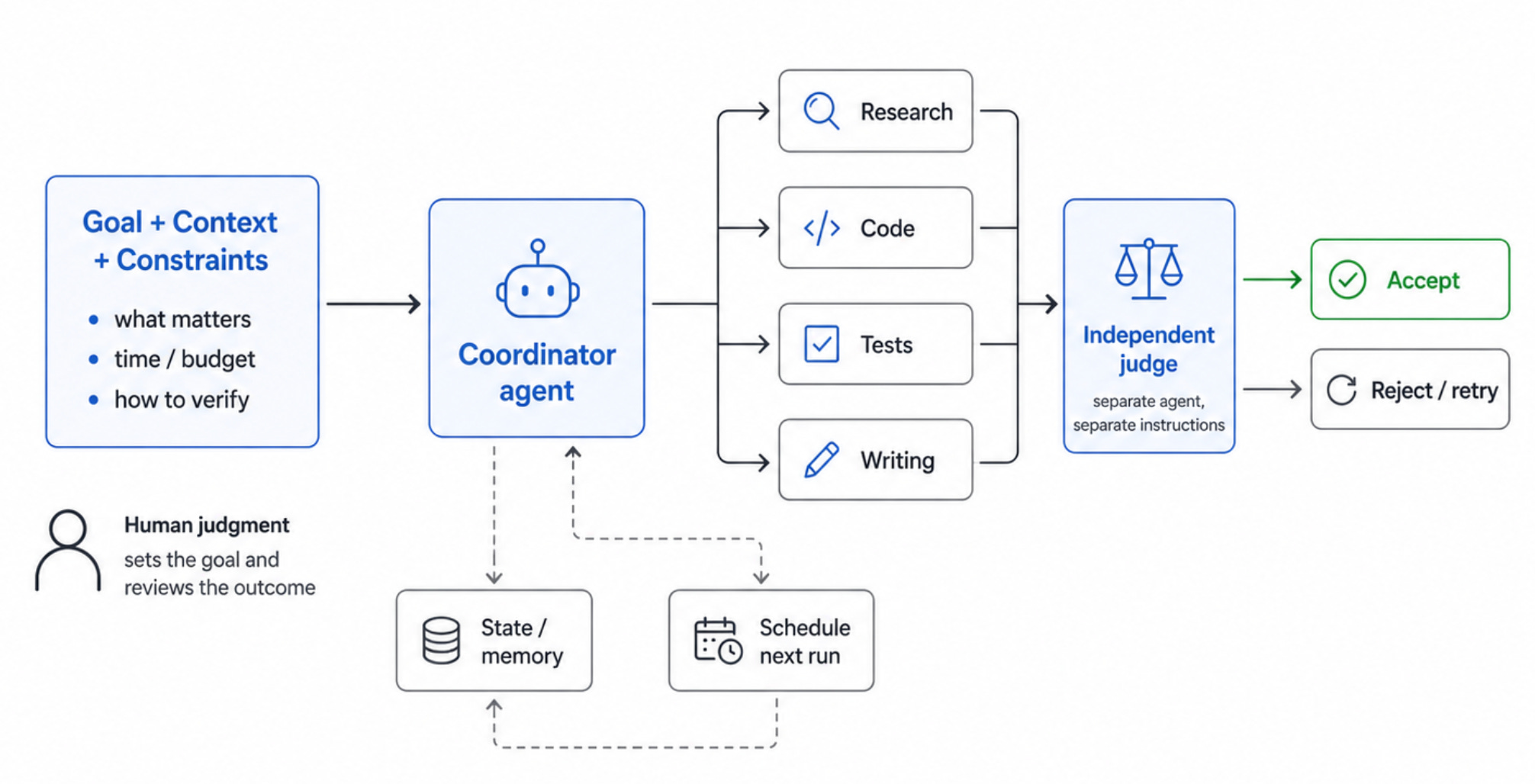
What is an agentic loop?
Compared to our deterministic for/while loops in our favorite programming language, an agentic loop has a different structure:
Discovery: it finds each turn's work on its own (reads CI, open issues, recent commits, support tickets, metrics changing, etc.).
Handoff: it gives the task to a specialized agent in its own isolated workspace
Verification: a different agent says "yes" or “no” to the result (LLM as a judge)
Persistence: it writes state somewhere (outliving the conversation)
Scheduling: it kicks itself off again later.
All these steps are necessary:
No discovery? As humans, we overthink and spend too much time deciding what we should work on. Agents don’t care, they pick what’s available, just give them a space to fetch that.
No persistence? You want cumulative progress. Agents forget everything the moment the context window clears. Memories help avoid rediscovering the same things, redoing the same work, and creating conflicts.
No scheduling? A loop needs a trigger to start
No isolated workspace? Run two agents in parallel against the same working directory and regret it. One worktree per task. Always. (I find Conductor nice)
No verification? Don’t even think about removing this.
Verification is the crux of everything
Ask an agent to score what it just produced and it will praise itself. The context in which the code was written is already stuffed with the reasons it was written that way. So when the agent looks back at its own output, it doesn't see the result, it sees the chain of self-persuasion that led there.
It’s why in Claude, /goal calls another agent, not the coder agent, to act as a judge and assess what was produced. An LLM-as-judge that shares the whole writer's context and reasoning is useless for the same aforementioned reasons.
A separate evaluator, with its own instructions, just knowing the goal and constraints of the work, defaulting to doubt, is the only way to act as an independent judge.
Making the writer more “self-critical” doesn't work either. You can't ask an author to step outside their own perspective. You can swap in another agent with entirely different instructions that looks at the code cold, carrying none of the self-persuasion. I use the Codex skill in Claude for this. Codex is a great judge.
Note that the judge agent should act, not just read some output. It needs to run the tests, open the page, click the button, take the screenshot, inspect the DOM, etc. to form its judgment. You often judge a behavior, not a book.
That's exactly what my runaway workflow did: it didn't ask an agent "is this correct?", it wrote programs that proved correctness.
Agents never just do “nothing”
For some reason, I heard some people worried about agents getting stuck, doing nothing, wasting tokens and time. But agents are programs, they don’t stop. They always do a lot of things, fast, confidently, … but many things they do are often detrimental:
Missing checks. Merging PRs without verifying they really work. Then CI starts to fail.
Your ignorance is growing. Your agents ship code you didn't write or review: the gap between what exists and what you actually understand is growing.
Getting average. When the loop runs itself, it's tempting to stop having an opinion and just take whatever it hands back. It will average everything, decisions, code, use-cases; what will be generated won’t be what you expect.
Tokens/Quotas. An agent creating loops, evaluating and building a ton of things, retries, runs round after round, and you can say bye to your quota if you have one.
There is a synergy between all of them:
The more the loop produces unverified, the less you understand.
The less you understand, the more you surrender.
The more you surrender, the longer it runs unwatched.
The more you pay.
So where did the value go?
Back to the statement: Cheap Generation, Expensive Judgment.
It's the oldest rule in economics: when something gets abundant, its price decreases, and everything built on top of it rearranges.
Loops make code, plans, fixes, and PRs abundant.
A single person with a well-built loop or loops can produce the output of a small or large team. This does not mean it makes software engineers less valuable. It means good software engineers, with comprehension, context, and judgment, can work with scarce information.
This is what changed: good judgment itself is scare. Judgment is about deciding which of the abundant outputs to keep. You can generate hundreds of candidate implementations, but who can tell the one to keep? "This one is right" is exactly where engineering has always lived.
The value moves from "writing code" to:
what to accept and what to reject,
where to draw the line,
where a human has to stay in the loop on purpose,
what the goal and the constraints actually are before any of it starts.
Those are more or less the content of the prompts I always give to Claude. That’s the whole act of engineering. Everything after is execution, and execution is becoming free in human attention.
Said differently:
If your role and value was mostly mechanical labor and following workflows, that value is evaporating, because the loop does all of it.
If your value was judgment, it's amplified, because the loop executes your good decisions a hundredfold.
This widens the gap between the two kinds of engineer. When hiring, you now have to value people for their taste and judgment, not which company they come from.
How to make a loop?
Here's a simple and complete loop to find and fix CI issues, with all five stages we’ve discussed:
Scheduling: Cron, every morning, 6am.
Discovery: invoke a skill, not a wall of text glued into a cron job nobody will update. "Read CI runs that failed since yesterday, issues opened in the last 24h, commits merged since the last run. For each, decide: is it worth acting on?"
Persistence: write findings and their status to a state file (a markdown file, or a Linear board). I’m a huge fan of Linear for this.
Handoff: one isolated worktree per finding, so parallel agents don't collide (conductor.build is great for this).
Verification: a second agent reviews against the tests, and a fresh small model checks the stop condition (/goal: run until tests pass and the lint is clean, judged by a model that didn't write the code).
Human review: PRs get opened.
What's left for humans
The judgment, not the typing. Generating is free. The scarce resource is knowing what is right, why, the context, the constraints, the how-to-verify.
The loop produces. The human still has to know what “good” means.
My loop is much simpler. I have a dev agent, who loop on working down the GitHub priority list and generate PR. that's all it does. Before it takes an issue off GitHub it will check existing usage, and will only proceed if it's < X% used. If it ran over will sleep and wake up when the 5h limit or the week limit hits reset.
The other agent (specifically from a different LLM) will review, test, approve, merge PR.
I still get heavily involved in generating a PRD, which is the only source of new feature work that gets turned into issues, that's how I ensure I know what the heck is going on.
My project is small so this two agent setup works. for larger project having multiple dev and reviewers should work, as any new PR is a branch off main, and dev agent will rebase to main to pickup anything new before tackling any new tickets.
The usage check s key so I do not overrun my budget (I am getting by on a Claude PRO account as this is a personal project and I am retired)...